Learning to speak pykts
Or how to create your custom Optical Characters Recognition (OCR) system using python and computer vision.
Backstory
I am a big fan of ‘realistic’ comic books characters. The ones that don’t actually have super powers but are just apex humans that use their top level physical and cognitive capabilites as super powers. One of those is Mister Terrific (well if you don’t consider being an olympian in several fields, 3rd smartest man alive a super power of course).

So of course, once I heard he was part of the investigation about Adam Strange in the strange adventure 2020, I read it. In this story, Adam Strange is warning earth of the coming invasion of some extraterrestrials called the ‘Pykts’. During his investigation, Terrific was told that their language had never been translated. However, he was able to teach himself their idiom.

That’s when I realised that actually, the pykt language seems to be nothing more than good olf english with a different spelling and that I could maybe use those few words as a Rosetta stone. Making it an OCR task, not a translation task.
Methodology
- The first task was to extract all characters from this few words. My alphabet is actually only 17 characters long which is not a lot but can hopefully already be enough to make sense of the words once translated from pykt to english.
I did so using the Otsu filter. This filter can be used to differenciate between background and front of an image. It does so by defining an optimal threshold that diferenciate the two classes (front and back) based on the grayscale level of the pictures’ histogram.

In my case, the extraction was relatively straightforward.

The difference between front and back is quite obvious with the letters being in black on a white background. A bit of trial and errors and tweaking allowed me to find the optimal threhsold.
- However, this method had some drawbacks. It extracted all the characters from the pictures, including typographic signs that I don’t want to extract. To tackle this, I took the average size of each of the extracted characters exctracted the characters again only when their size was bigger than the average size of the letters, thus getting rid of the typographic signs.
Then I took the average size of the letters and resized all extracted characters to this size before saving the letters in greyscale. - Using the Otsu method had one other drawback though, the letter ‘A’ was extracted as two characters that I called ‘a1’ and ‘a2’.
The resulting alphabet was:

Finally, I also extracted the position on the x axis (left side) of each letter. I’ll be using it later to compute the variation of distance between each character and separate words from each other.
- A drawback of this method is that the implementation of the otsu filter does not extract the characters from let to right and top to bottom, so I have to make sure to give an input image which is linear.
For the reading part, each character extracted from a new unknown picture will be compared to the alphabet using the cosine distance. The smallest cosine will be deemed as closest neighbor and therefore as a translation from pykt to english.
Process

For a new image, the process will be to convert it to greyscale, apply otsu filtering for extraction, compute average size of the images, save only images which dimension are equal or greater to this average, extract the x position of each image, compute the average distance between images and the standard deviation, compute cosine similarity with the alphabet to extract the closest english letter, consider that if a character is located at a distance eual or greater to average distance + standard deviation of the distance it is part of a new word and finally, replace all ‘a1a2’ by a single ‘a’.
Results
I’ll first crosscheck the performance on the image I used as a rosetta stone
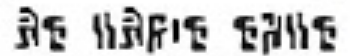
expected output: it aint that
given output: it aint that

expected output: impossible
given output: impossi ble
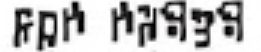
expected output: now where
given output: now wwere


given that both letters are quite close, this is understandable.
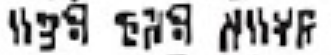
expected output: are the damn
given output: are twe damn
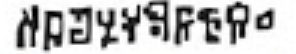
expected output: documents
given output: docume nts
It translated:
- It aint that impossible now where are the damn documents
- It aint that impossi ble now wwere are twe damn docume nts
The results are not bad, it tends to read h as w and to see spaces where there are not supposed to be but it does a decent job.
I will now test it on a new and unknown document

Translating the first sentences using this piece of code gives us:
- hou mia2wt waa2e surrende re d and lia2ed as slaa2e s but hou waa2e cwosen conmlict as sucw twe onlh limitation set upon om twis warmare is wow a1uiculh hou will die
Using this partial translation, knowledge of the limits of the script and basic english, I guess it was supposed to mean
- you might have surrendered and lived as slaves but you have chosen conflict as such the only limitation set upon on this ‘warmare ?’ is ‘wow a1uiculh ?’ you will die
which is once again a decent result, one can get the general meaning of the speech here. Moreover, it enable to extract the letter ‘y’, ‘g’ and ‘v’ to enrich the alphabet and make future translations more efficient (which I may do in future iterations).
Improvements
This implementation is very simple, moreover, givent that the input was already of good quality, the translation is easier and no additional manipulations are needed (like denoising, sharpening…). However, the alphabet is still quite limited even if I can already add 3 more letters resulting in better translation and little by little reaching 26 letters for optimal translation.
Moreover, adding some text processing (jacquard distance based on a dictionnary, reccurent network) could be usefull as well to correct spelling mistakes and providing an even better translation.
Sources
github coming soon
